source: https://arxiv.org/pdf/1806.04356.pdf
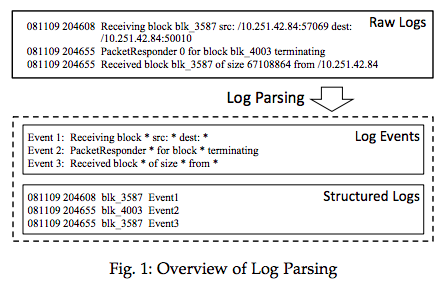
日志解析就是将原始日志转化成结构化日志,并从中抽象出日志事件的过程。
Algorithm
Drain是基于有向无环图(DAG)的日志解析方法,分别通过以下五个Layer:预处理层(Preprocessing Layer)、长度层(Length Layer)、记号层(Token Layer)、相似层(Similarity Layer)和输出层(Output Layer)。
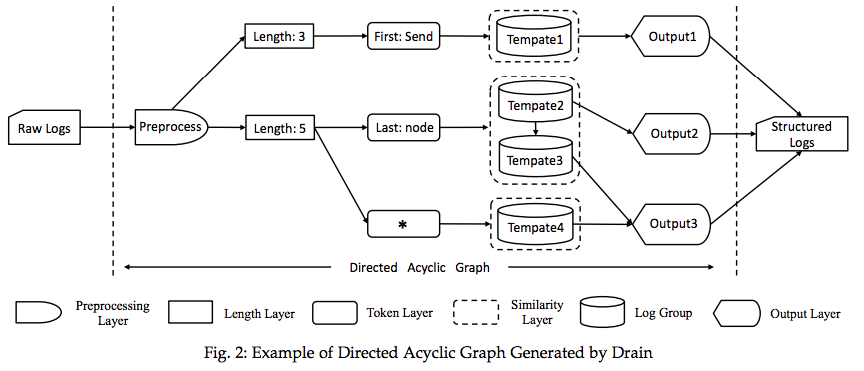
Preprocessing Layer
将通用的Domain Knowledge如IP address,filepath整合起来,先对原始日志进行预处理。
这里处理的方式和之前的算法不同之处在于,用block_**替代block_123而非将block_123*删除
原始日志
Received block blk_3587 of size 6710864 from /10.251.42.84
其他解析方法预处理(blk_*, /filpath都被去掉)
Received block of size 6710864 from
Drain
Received block blkID of size 6710864 from Filepath
Length Layer
基于相同事件的日志长度相同的假设,将日志根据长度分桶
Token Layer
这里定义了split token,日志根据split token进一步分桶
Drain考虑了三种情况
(1)第一个token是split token
(2)最后一个token是split token
(3)第一个和最后一个都不是split token
如果log的第一个token和最后一个token都包含了数字或者特殊符号,那么就属于第三种情况。
Similarity Layer
按照split token进行划分之后,将日志与桶内存在的日志组所对应的事件签名log event signature进行相似度比较
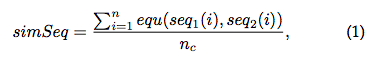
seq1代表该条log,seq2代表log event signature,n为日志长度,nc为seq2中非wildcards的数目
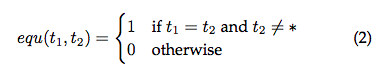
如果simSeq大于similarity threshold st,那么log属于该日志组,同时更新log event signature
如果找不到满足上述条件,那么新建一个日志组,把该log添加进去。
Output Layer
针对相同事件可能存在不同长度的问题,提供了一个optional的融合方法来解决。
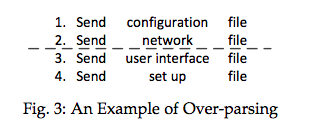
最终合并成
Send * file
Cache Mechanism 缓存机制
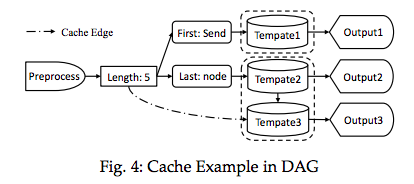
超算生成的日志通常会连续地生成相同格式的日志,因此Drain定义了一个Cache Pointer,定位上一次Template的位置。该方法可以减少查找次数。
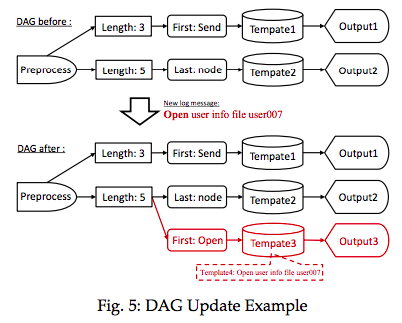
DAG更新
Update the DAG
Similarity Threshold Initialization and Updating
Initialization
不同的log group有着不同的st_init
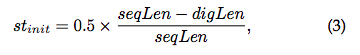
seqLen代表日志事件长度,digLen代表具有数字的消息长度。st_init表征了日志事件中const ratio的下界
Updating
st不是一尘不变的
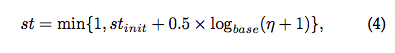
n代表每次log event signature变化时从const token变成wildcard的个数。
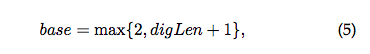
Merge Log Groups
合并不等长log event signature
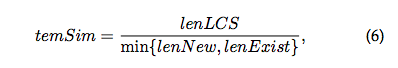
lenLCS表示LCS中token的个数,lenNew和lenExist分别表示新的log event和当前log event的token个数。
这里会定义一个merge threshold融合阈值mt,当temSim>mt时才会进行融合操作。