算法流程

LogMine将消息日志划分成相关的组,并且用最具有代表性的日志模式来代表每个类。再自底向上进行聚合直到达到root节点。在每个模型中,有三个类型的域:Fixed value, Variable and Wildcard。其中Fixed value field匹配诸如www, httpd, INFO这种独一无二的值。而Variable Field匹配一个确定类型但是具有任意值如number, IP address, date。而Wildcards匹配任意类型的任意值。
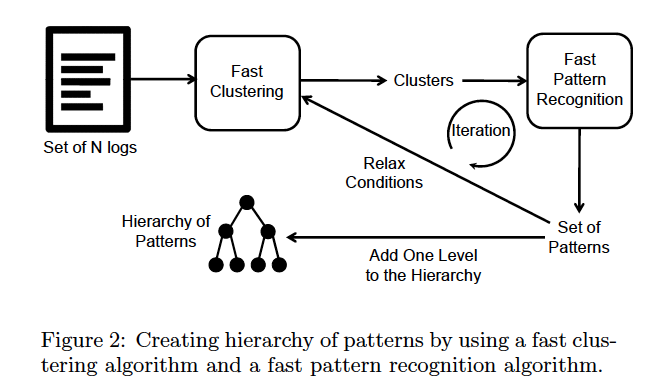
LogMiner将一批日志数据作为输入,通过聚类模块用限制性条件将它们聚类起来,在模式识别模块中生成每个类的模式,这些模型构成了层次模式中的叶子结点。这些模式接着用松弛条件继续聚合生成更泛化的模式,这些模式是之前模式的父节点。如此往复,直到生成根节点。
(1) Tokenization and Type Detection
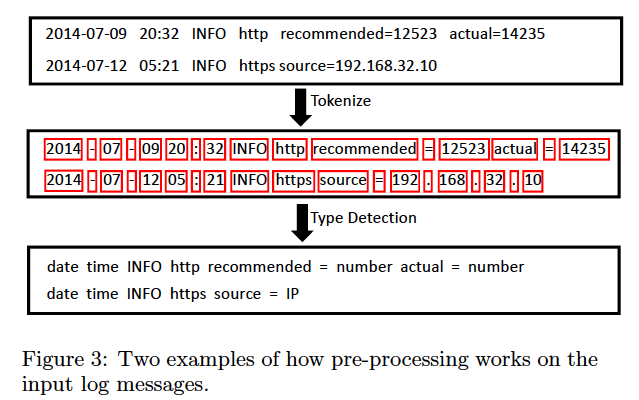
主要工作是用分隔符把一条日志切分开来,同时检测并替换预定义的类型(如IP,日期等等)。
(2) Fast and Memory Efficient Clustering
Distance Function
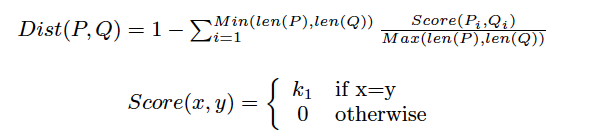
首先定义了两条日志P和Q之间的距离函数,k1是一个可调节参数,默认为1。
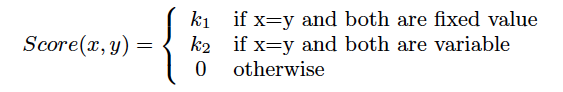
将score进行一番修改,可以定义两个cluster patterns之间的距离函数。默认k1=k2=1,
- Finding Clusters
定义了内部参数MaxDist,该参数限制了一个类内日志和类代表日志之间的距离的最大距离,则同一个类内任意两条日志之间的距离不超过2MaxDist。每个类都有一个代表性的日志消息,即属于该类的第一个成员。对于任意一条新的日志消息,当且仅当与类代表日志之间的距离小于MaxDist才进行插入操作,否则新建一个类,并将该日志作为类的代表日志。
因为每个类只需要保留代表日志,所以节省了内存空间。仅需O(number of clusters)的memory usage。
- Early Abandoning Techique
采用Early abandoning 来加速Euclidean distance的相似度搜索。粗暴点的说法就是field by field时候,如果距离超过了MaxDist,那么就提前中止两个log的比较。
(3)Log Pattern Recognition

对每个group生成对应的pattern,因为group里日志长度不尽相同,所以需要对日志进行最佳对齐。最佳对齐是指用在融合时候用最少的variable和wildcard。Align算法采用了Smith-Waterman,操作步数为O(l1l2),l1,l2是两条日志的长度。

作者认为每个group里的log都是近似相同,所以日志的输入顺序不太有影响。
(4)Hierarchy of Patterns
模式的层次结构可以提供日志消息的整体视图,并且管理员可以在层次结构中选择具有正确特性的级别来监视异常。构建层次的过程是一个bottom-up的过程。为了建立不同层次水平的log pattern,通过调节alpha乘积来调节MaxDist,在每一次迭代过程中,都是增加了一层的pattern。
在Hybrid Pattern Recognition中,因为放宽了MaxDist的限制,group里的log都不尽相同,所以前面的Sequential pattern recognition算法不适用。但因为非叶子结点层中的group里的pattern个数有限,可以采用selective merge order中的非加权组平均法UPGMA算法。
th1定义为一个类中pattern的密度阈值,th2定义为一个类中pattern的个数。
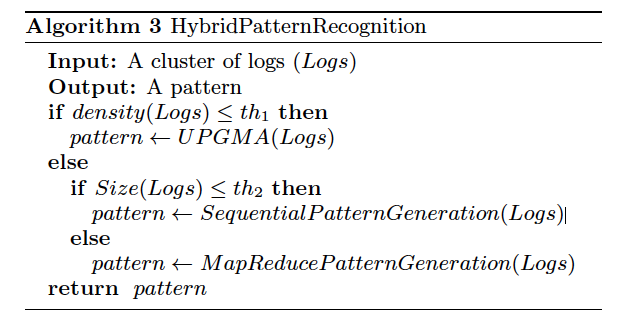
作者这里定义了一个cost函数, 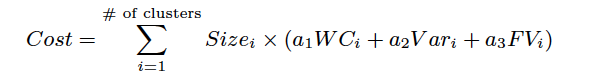
Size_i是类i中日志的个数,WC_i代表wildcards的个数,Var_i是variable fields的个数,FV_i是fixed value fields的个数,a_1,a_2,a_3是相应的参数。pattern的选取为相同层的pattern。